Concepts and development of Open-RMM
Apr 5, 2023
Disclaimer: this post is mostly to dump ideas from my mind and make the project goal more defined.
What is Open-RMM?
The Open RMM is project I am working on. It is Open Source RMM (Remote Machine/Monitoring Management) solution, mostly intended for homelabs (my homelab) and in the future maybe even something more.
Quick look on the WIP dashboard for RMM.
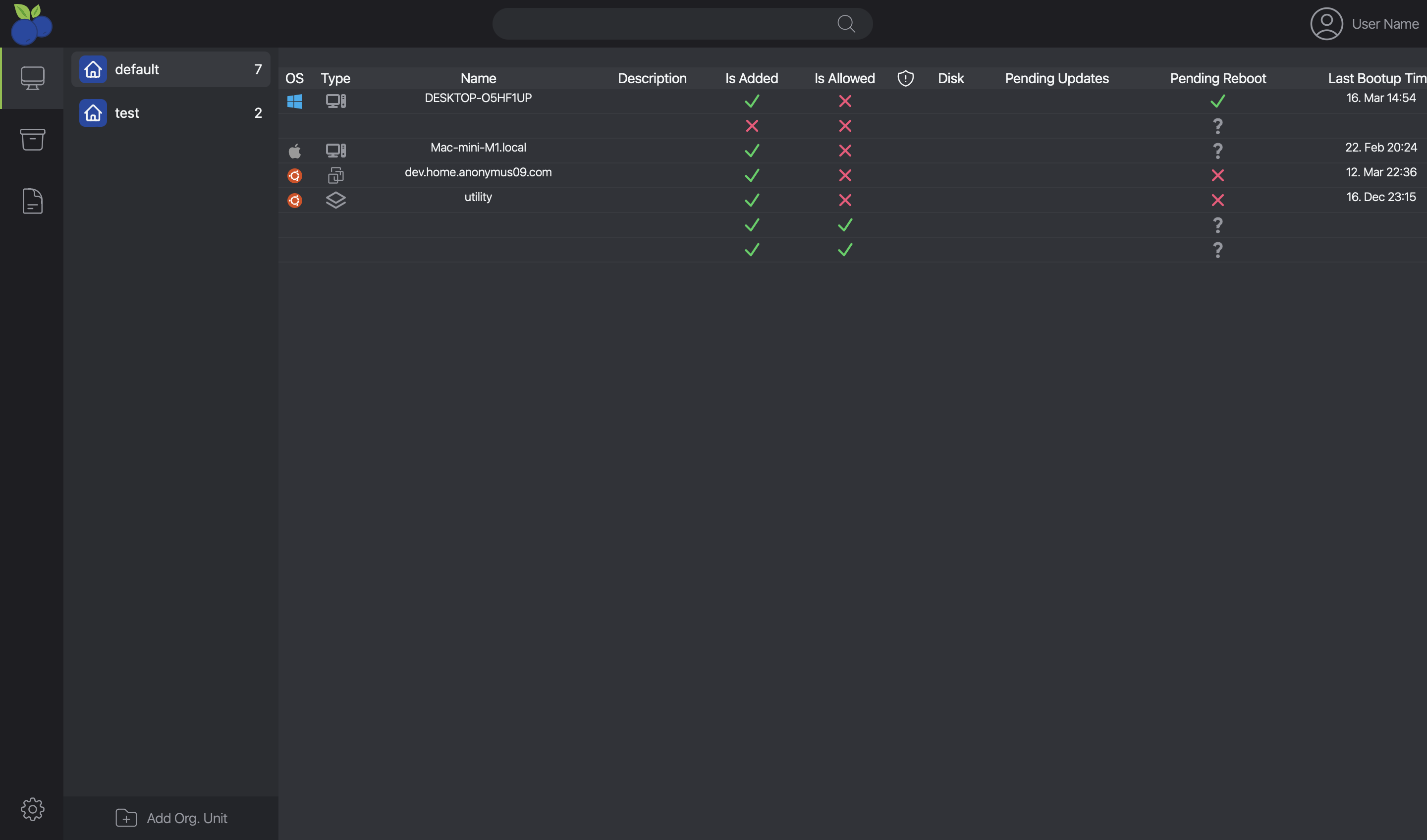
Why I am making Open-RMM?
There are multiple Open Source (or at least free) RMM solutions: MeshCentral, RPort, Remotely, RustDesk. But none of work or look how I wanted/expected. In my day job I use N-Able RMM so there are some ways I am used to how they work and look. But also there are things I hate about it, so it is not my intention to just clone it. Second reason will be, I needed some kind of long term project to work on (when I have time and motivation). Also I always want to learn new technologies so this is my excuse and also reason for so many rewrites.
What is the goal of Open-RMM?
The goal is to be full solution to monitor status of your Computers, Virtual Machines and Containers (LXD not Docker), to be able to connect to them (how to do it is still TDB) and to be able to simply deploy the Open-RMM in you homelab.
What features are you planning?
This is high level overview
- Dashboard with list of computers and their status, separated into Org. Units
- Support of Windows, Mac and Linux
- Small agent running as Service/Daemon
- In future to be able to connect to the remote terminal or desktop
Full past timeline of the project
2021
- First commit on 21. September, started with Svelte web, Express API and Powershell script as client agent. Used MongoDB in the backend
- Later in September moved to SvelteKit, had issues with understating the difference
2022
- January 2022, updated the packages, a lot of struggling with Svelte and Mongoose because of bugs
- Later in January 2022, found great tutorial by TomDoesTech on how to do APIs with Express, TypeScript, Mongoose and Zod… so the first rewrite is here
- January to early Feb 2022, pushing the work on API server for collecting the data
- Pause until July, again issues with updating packages, work on tests with Postman
- Early August, split common code to separate package, work on web part (used personal web as template)
- Another pause until end of October, another rework this was a big one. Started to use SvelteKit as fullstack so now using it for the API and also started to use Tailwind and Prisma (moved to Postgres SQL). This was full frontend and backend rewrite
- All of the November, worked on the new fullstack rewrite
2023
- Pause until end of February, found TRPC SvelteKit framework so of course need to rewrite the Frontend ↔️ Backend communication to use it
- Early March work in the UI, new colors, icons and layout, also work on TRPC implementation and removal a lot of unused code
- In the middle of march March, shifting to backend work with another rework, to work on separate collection server with Express (a lot of thinking to use something different like Go or Rust). Moved everything in Turborepo and pnpm, a lot of struggling with it, barely working.
- Until end of the March, have some of the API and UI working so need to work on Client/Agent for reporting the data. Got converted by Rusticians to use Rust so starting to work on Agent in Rust, a lot of struggling but I can see the appeal. This was technically another rewrite, because of the Agent was first intended to be written using Electron with PowerShell/bash scripts.
Number of rewrites 4.
Will try to update the timeline in future.
Why so many rewrites?
Well, where do I start? This is just a hobby and I am little too much enthusiastic for new technologies/frameworks I find. So I want to try them all. But also I am learning this as I go so I may start with something and learn new stuff so I wan to do it more correct/modern way. So probably there will be a lot more rewrites in the future.
So what tech stack are you using now?
- Prisma, I didn’t mentioned it that much but it was game changer, it is just fabulous ORM and it supports multiple databases
- SvelteKit, I just love Svelte and SvelteKit, it is getting better and better with each update
- Express, it is nice for API server with really nice customization with Middlewares, but sometimes it just look so bloated with boilerplate
- Typescript, of course I will newer go to JS
- Zod, must have for API endpoint input validation
- TRPC Sveltekit, this is just awesome way to write Backed ↔️ Frontend communication, wish I could use it outside of fullstack (may be possible but to much to research and broke)
- Rust, using for the reporting Agent, love the Cargo ecosystem and when your code will compile there will be no issue. Its syntax and concepts are somewhat alien to me coming from higher lvl languages with GC like C#, TypeScript (JS), Java…, but I like it, it just fights with me all the time
- May use Tauri in the future if I will need GUI for the Agent I think this is it, will try to update if something changes
Why did you go back to Express for collection API?
SvelteKit for fullstack is great and with move to TRPC, I had some questions about the API. I still can use SvelteKit for collection API and it would work but was thinking about separating this so I can in the future update Web and API separately. This also started the migration of the whole project to Turborepo, I need access to Prisma client from two different projects and Turborepo was the tool to achieve this. The migration was struggle, still it barely works but it works and that is what I need. I opened the old Express code I written before removed all the models, controllers and services. It just made hard to lookup anything and to remember where the code I need to look at is. I reduced it to the minimum just using Prisma to for DB, validating data with Zod and that is it.
Why did you go with TypeScript and Express for API server?
I was thinking about to moving to Rust or Go. Rust is super safe and fast, the code I did look up looked pretty clean and easy. Go was more less made for writing APIs, their handling of JSON is just brilliant, but I somewhat don’t like how they handle packages (Cargo rocks!). But I still did go with Node/TS/Zod/Express stack. It was for one simple reason… Prisma (and sharing of Prisma). I seen there are ORMs like Prisma but I still have to write models and schemas. The most thing I hate is writing the same stuff twice. That was the reason I did go with the pain of learning and moving everything to Turborepo. (Also I had written the whole Express server from last year…)
What is next?
Well, I hope I will continue to work on this more often and I hope I will get into stave there is at least somewhat useful. And for the post? I will see if I will update the post or make a new one when I will have some updates. Will see…
If someone read this, I am sorry ,it was just pure mind dump. I don’t think it made much sense but I hope there is at least some value.